Routing from a DNS perspective, On how it responds to DNS requests
Simple
- foo.example.com → a record → x.x.x.x
- multivalue → foo.example.com → a record → x.x.x.x, y.y.y.y, z.z.z.z
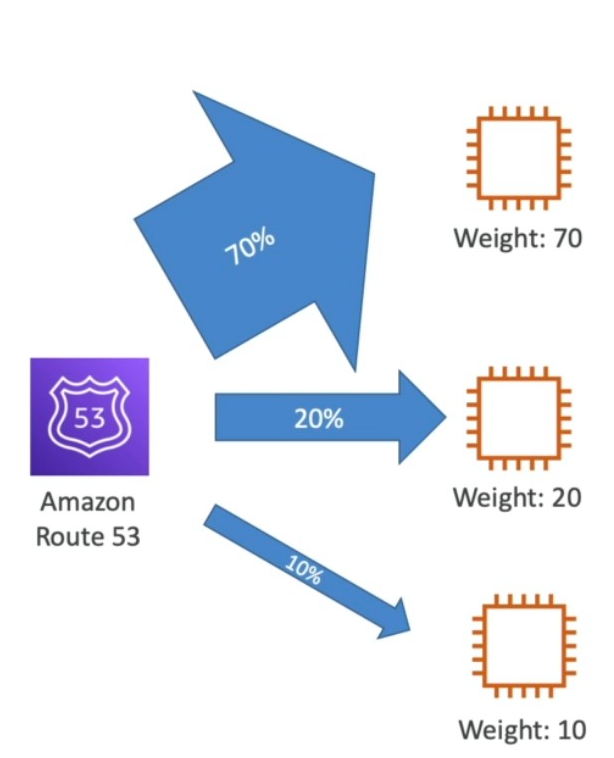
Weighted
- Assign weights to records with same name and types
- Record with weight 0, will get no requests
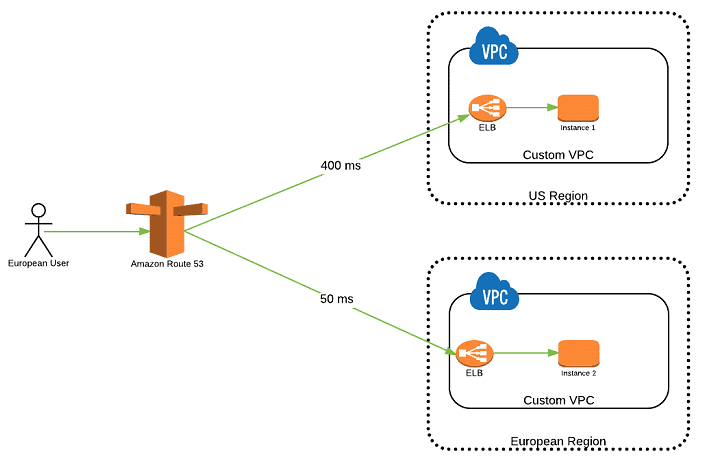
 Latency Based
Latency Based - Latency based on how close users are between AWS regions
- Routed to regions that has lowest latency
Failover
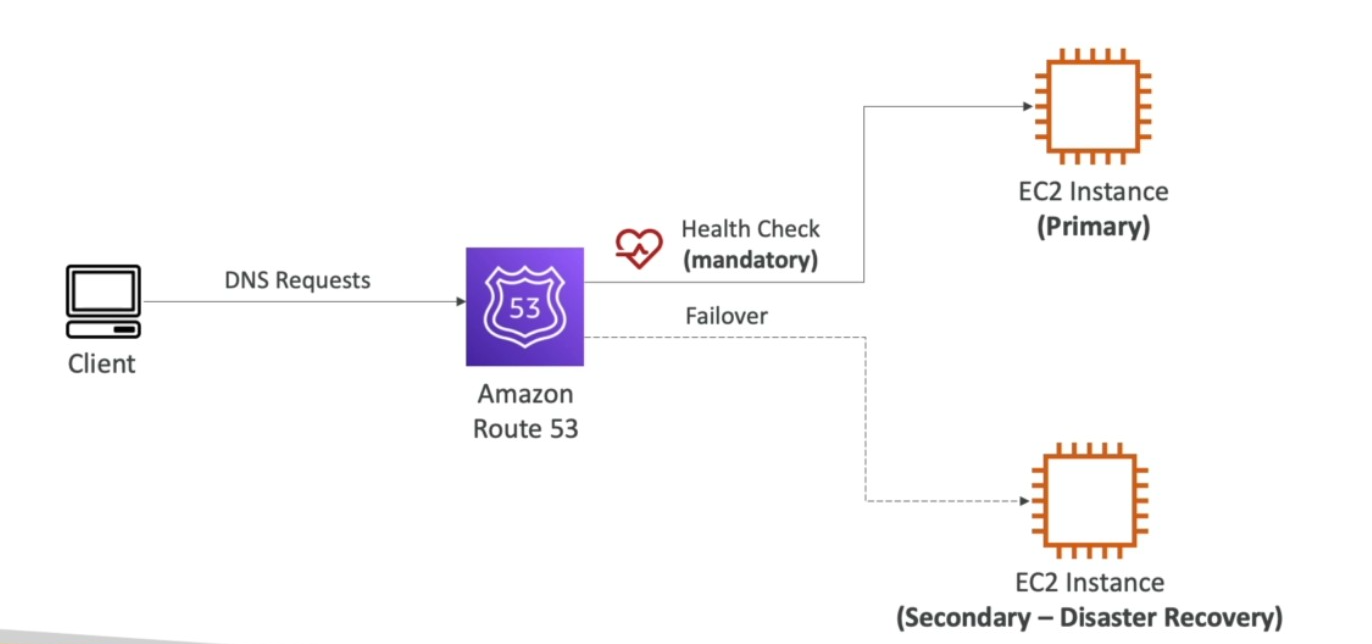
- You then configure in routing policy for a record, failover to a second record
Failover record type
- Choose Primary to route traffic to the specified resource by default or Secondary to route traffic to the specified resource when the primary resource is unavailable. You can create only one failover record of each type.
You’ll need to create two failover record, one as primary and other as secondary, by clicking on the add another record. The primary needs a health check mandatory
Geolocation
- This routing is based on location based, not latency based.
- But these have slight difference in their purposes. arent they? But this is more predictive
- We can direct to different versions of our app, based on location
- We have to have a fallback or default record for records that doesn’t match
- Configuration
- Create records with same name
- Use
add new recordbutton to add more locations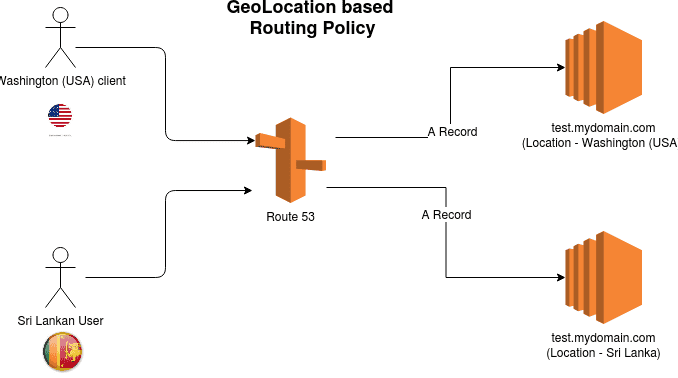
Geoproximity
Note that when learning for a certification (SysOps for example) always read carefully if routing should be done based on location of users (geolocation) or resources (geoproximity).
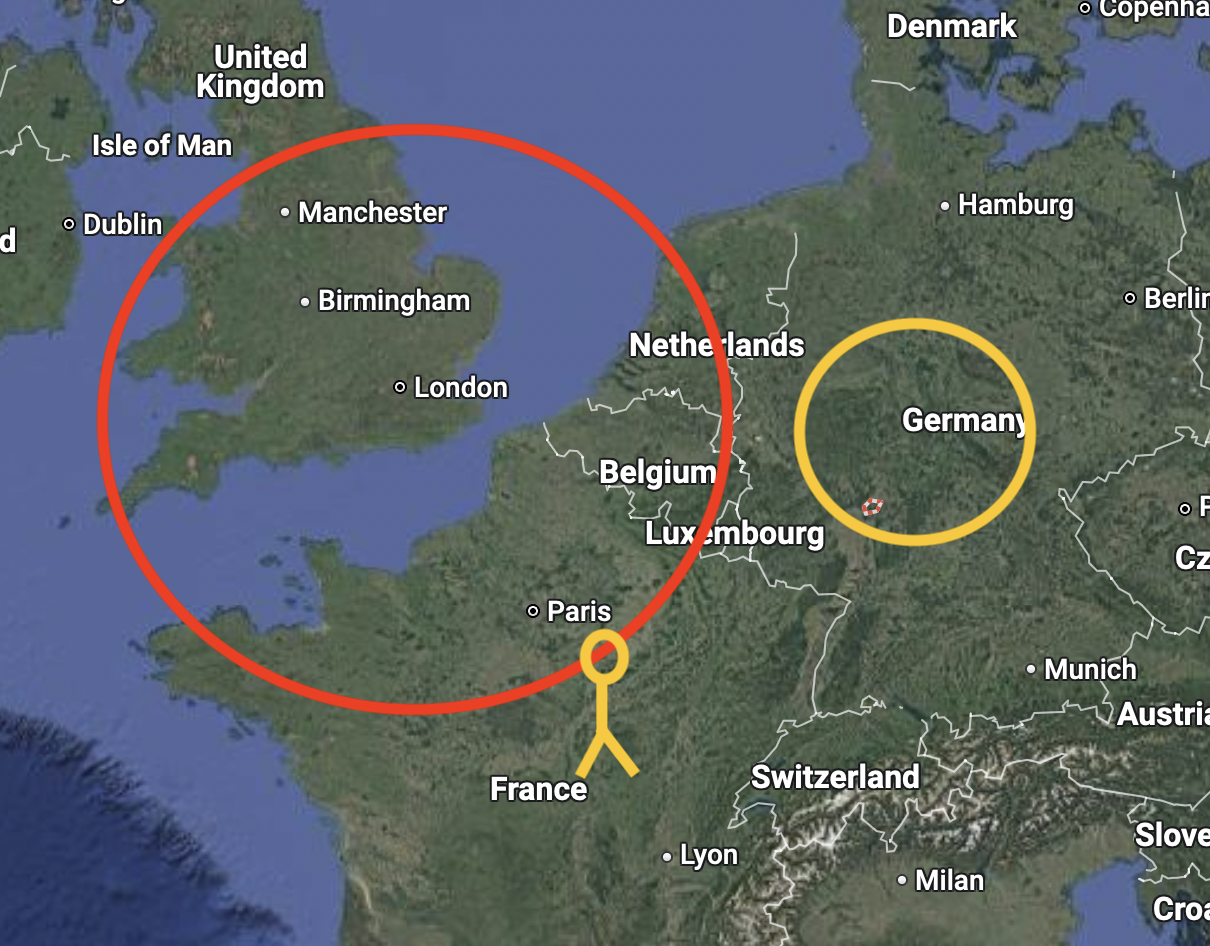
Geolocation is very static and predictive, you want all users originating from a place must go to this region. And Geoproximity is like saying, I want most of the traffic withing a radius (bias) needs to go to this resource
-
Geolocation routing is static and predictive: it directs all users originating from a specific geographic location (like a country or continent) to a designated resource or region. For example, all users from France might always be routed to the London data center regardless of other factors. This approach is straightforward but inflexible because it does not consider resource capacity or traffic load; it simply maps user location to a fixed target region12.
-
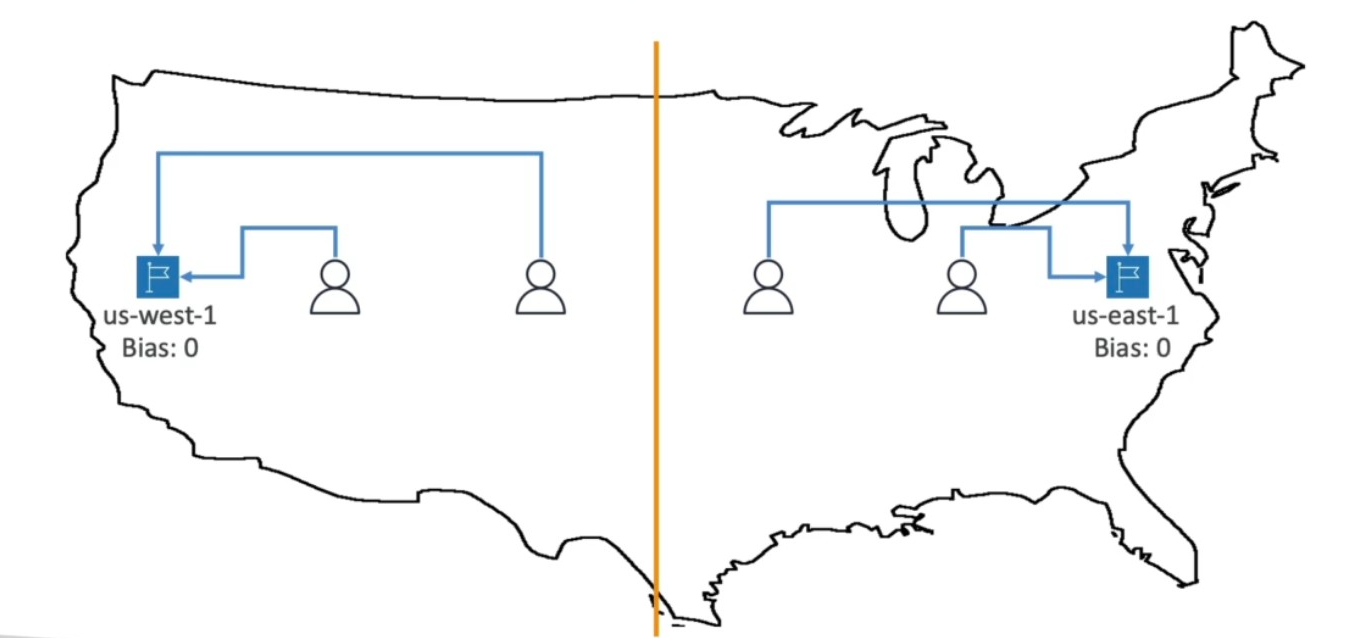
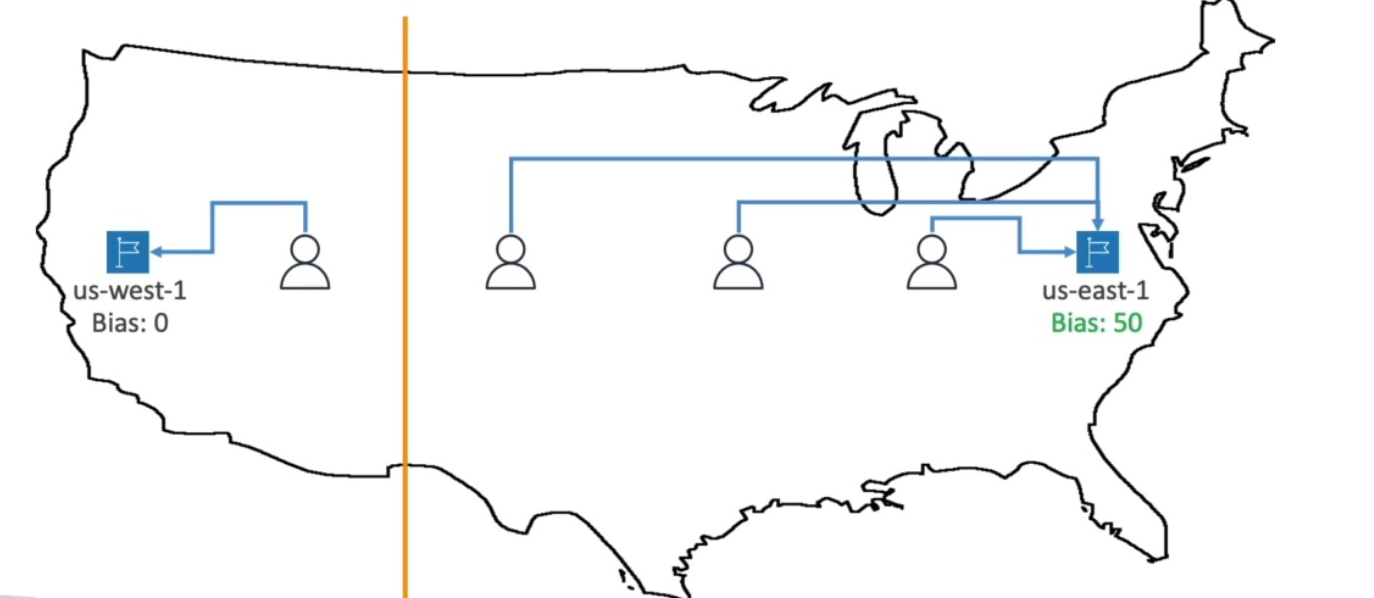
Geoproximity routing, on the other hand, is more dynamic and flexible. It routes traffic based on the geographic proximity between users and resources but allows you to adjust this routing by applying a bias value. This bias effectively expands or shrinks the geographic “sphere of influence” of a resource, meaning you can direct most of the traffic within a certain radius to a particular resource, but not necessarily all of it. For example, if you have servers in Oregon and New York and users in California, you might want to route a portion of California users to New York because those servers have more capacity, even though Oregon is physically closer. By applying a positive bias to New York, Route 53 treats it as closer than it really is, attracting more traffic from California1234.
Red circle - More resources, you assing more bias, yellow circle, low resources, low bias
 Traffic Flow
Traffic Flow
- Visual editor helps us to make decision
- After configuring we can deploy to a hosted zone
- Can be versioned, as its just a json code IP based routing
- Based on client’s CIDR range
- Useful if we know the client’s cidr range Multivalue routing
- Multiple A records without multivalue routing simply return all IPs regardless of health.
- Multivalue routing adds health checks and selective response of only healthy IPs.
- It provides randomized responses to distribute traffic roughly evenly.
- Clients will receive all records, and they pick. But they only receive health ones