What is Spark? Apache spark seen as popular alternative option for MapReduce. Spark uses YARN and takes advantage the HDFS and just delivers a faster performance than MapReduce.
How spark works?
- Driver program co-ordiates cluster tasks and orchestrates it
- The Driver program uses cluster manager (YARN, Spark’s manager) to know about resources available
- Executor are the workers that assigned of a Task and will have its own cache
Why spark is faster than that of MapReduce?
- MapReduce writes to disk after every Map/Reduce operation, whereas Spark keeps the results in memory
- Spark is based off of DAG, where as MapReduce is strict Map → Reduce cycles
- MapReduce is very chatty with Disk, slower
Where spark gets used often? Spark often used in ML pipelines, Stream Processing, real time analytics and graph processing, but not used for OLTP and batch processing acts as a transforming data as it comes
What are the components of Spark?
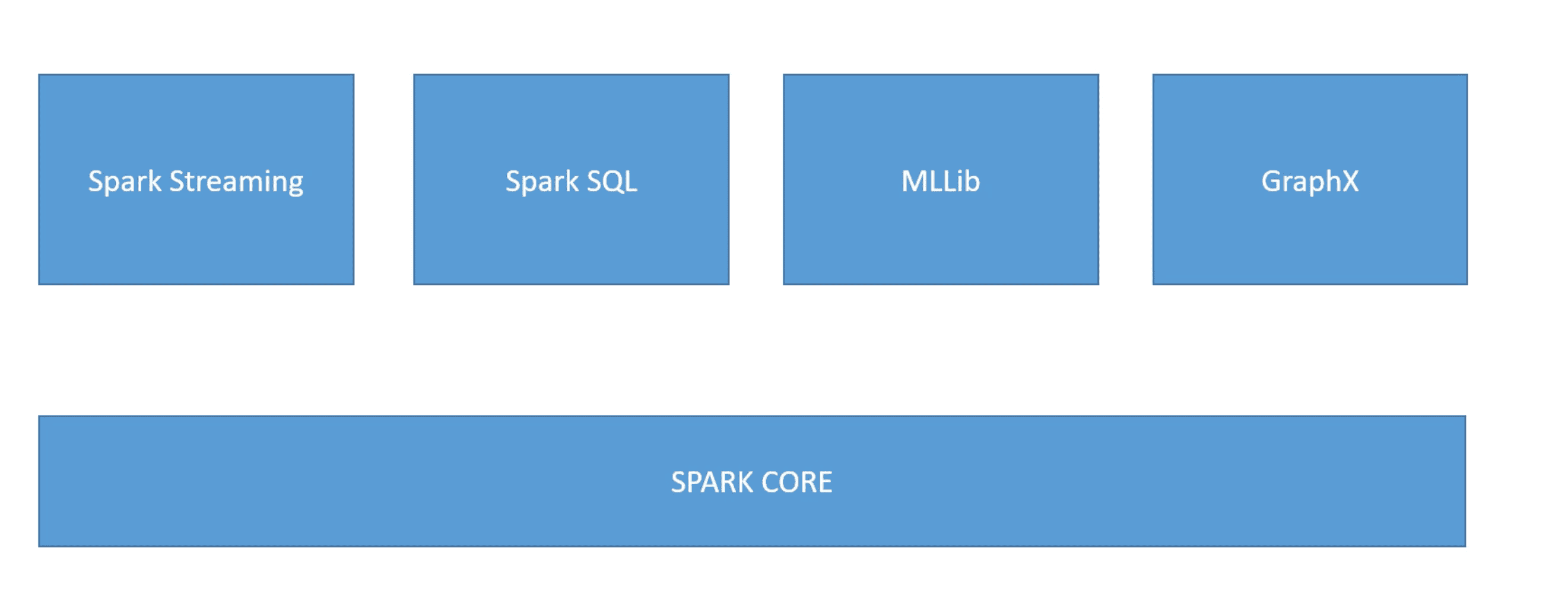
- Spark Streaming - Data ingested in mini batches from sources (kafka, twitter, flume, HDFS, Zeromq and also obviously AWS kinesi) and analytics gets applies as they come in. The same code used for Batch processing can be used here
- Spark SQL
- Spark MLlib - Machine Learning Library for Spark - Provides distributed machine learning algorithms
- GraphX - Distributed graph data processing, (graph of people in social network) - enables iterative graph processing and so on
- Spark Core - All the spark related lore - memory managements, interacting with stroage system, fault recovery, scheduling and distribution. Servers as common libs for other components