To improve loading times on ALB
- Setup cloudfront distribution
- NLB might help improve the solution, but won’t be scalable across the globe
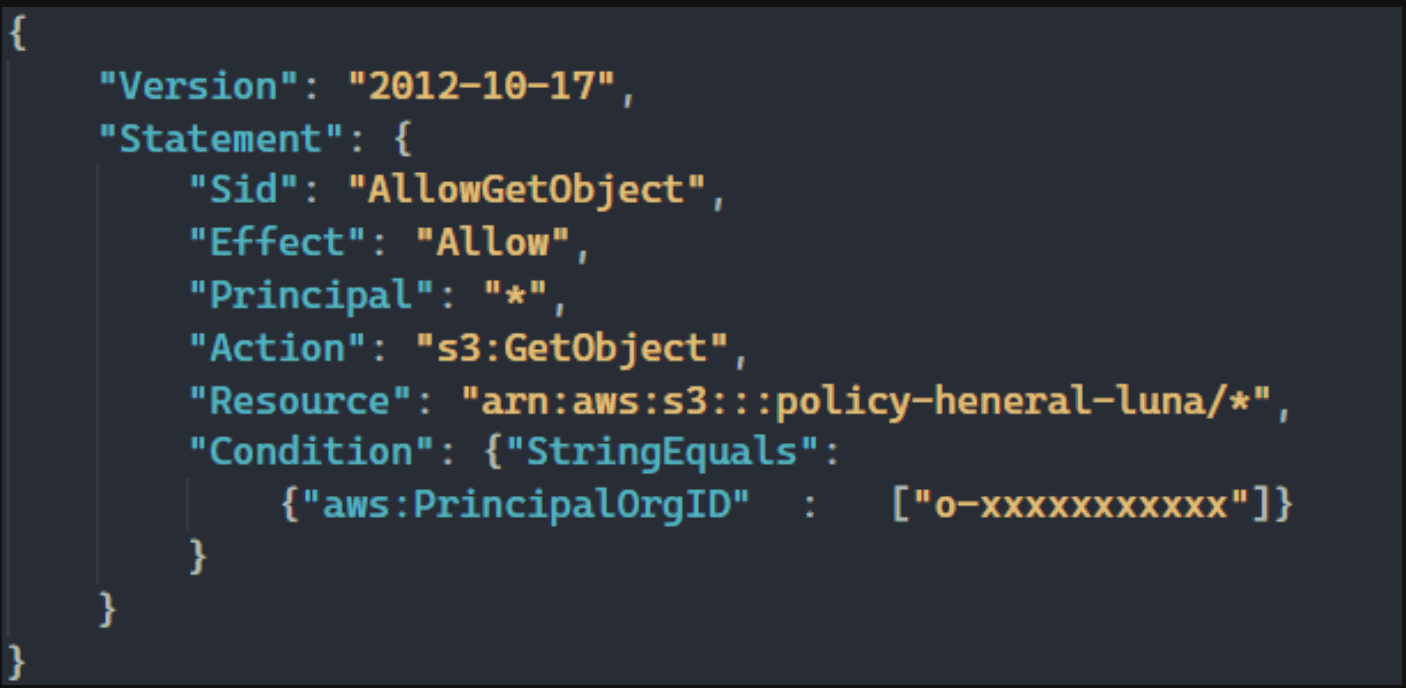
Limiting access only around organisation, you can’t directly specify an principal,
principal inputs
"AWS": "arn:aws:iam::123456789012:root" // Entire AWS account "AWS": "arn:aws:iam::123456789012:user/username // IAM user "AWS": "arn:aws:iam::123456789012:role/roleName" // IAM role "Service": "ec2.amazonaws.com" // Service "Federated": "arn:aws:iam::123456789012:saml-provider/MyProvider" "CanonicalUser": "79a59df900b949e55d96a1e698fba1bc14EXAMPLE" //canonicalUser - oac vs oai
Link to original
If you setup Secrets manager for RDS, Redshift, DocumentDB, Redshift cluster. The secret manager will automatically rotate the password using a lambda function behind the scences
Its better to use s3 hosting for static pages and take the load off of a database. Use elasticache when the content is frequency fetched from the database. Read replicas for read heavy database workloads
health-checks Apparent health to yes,tly you can set this evaluate targe which enables health checking and failover if the resource deemed to be unhealthy. 
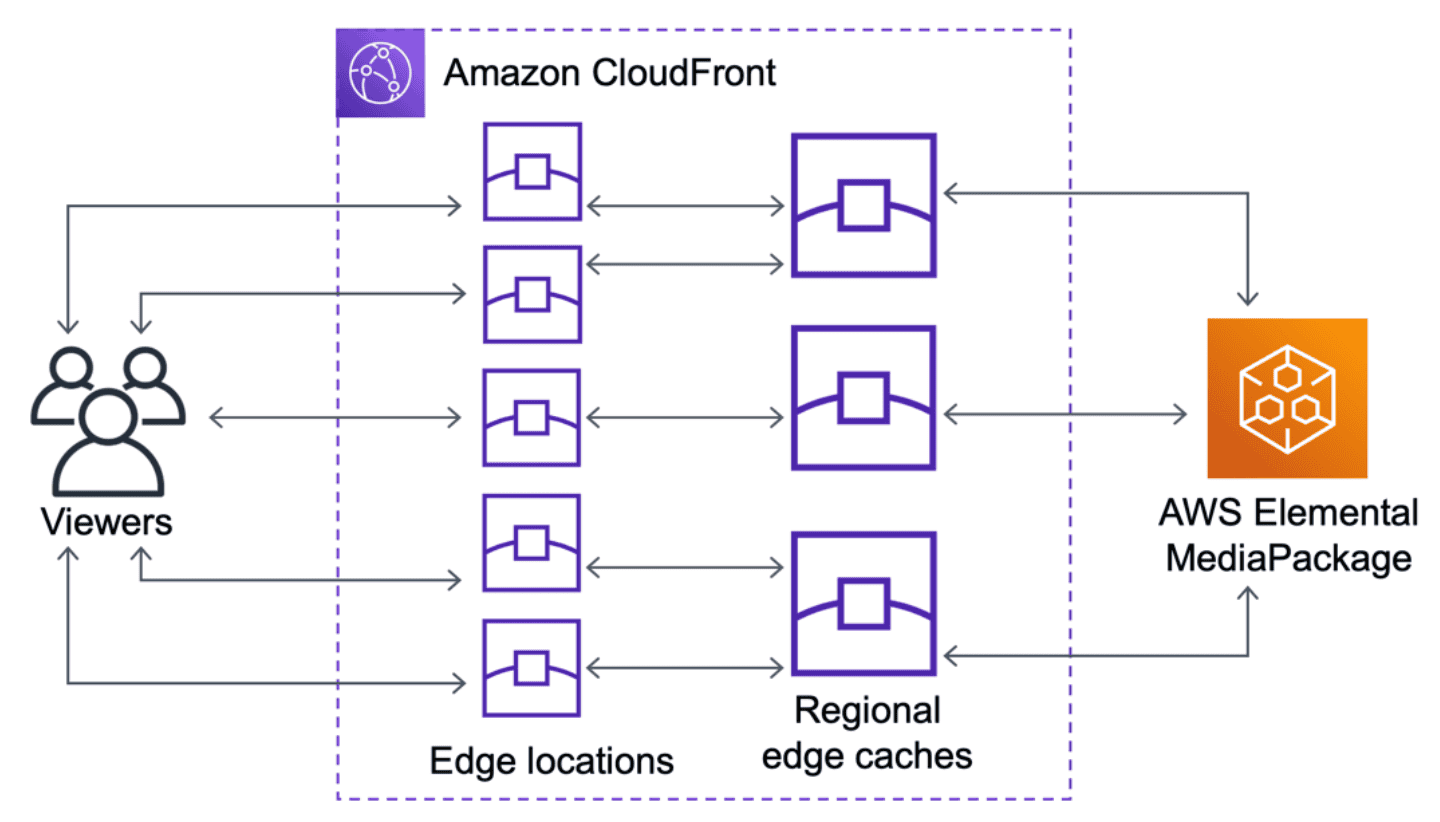
Cloudfront origin shield - additional caching layer
CW alarm if all instances became unhealthy
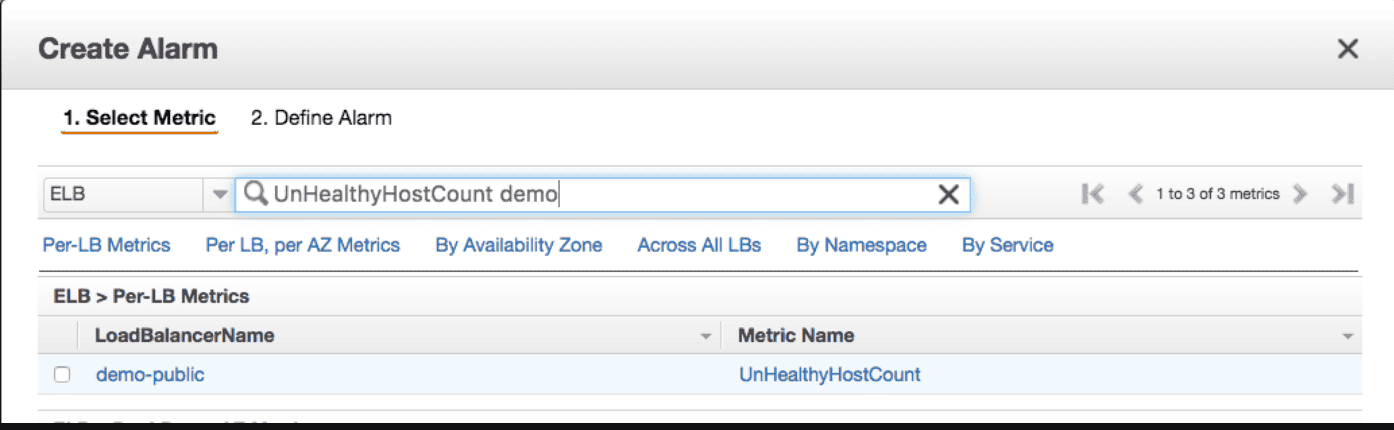 and dfine the alarm as
and dfine the alarm as HealthyHostCount <= 0
Backups and Auto Scaling in RDS and Aurora
-
RDS backups data with user configurable 1 - 35 retension days
-
Aurora backups are continuous and incremental and retained up 1-35 days
DiskReadOPS is only for instance store instances that will displayed under EC2 metrics. most of the EBS volume metrics starts with Volume*
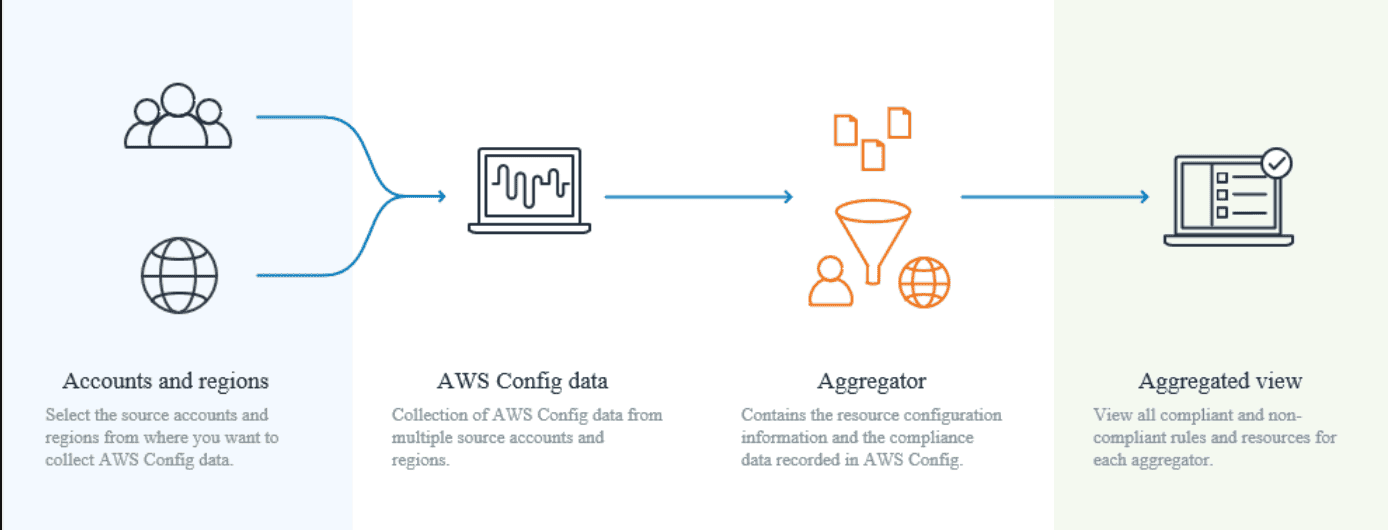
You can’t setup AWS Config aggregator on All AWS Resources in a organsiation, but you can seutp AWS config aggregatro on All AWS Accounts in a organisation. You’d need to enable in all accounts
Cost related services
- You can use CUR for reports
- you can use budgets for alerts
- You can use Cost Explorer usage trends and forecast
- You can use Billing Dashboard for pay outs and current month spends
Detailed monitoring
- EC2 instances that have detailed monitoring enabled. Instances that use basic monitoring are not included for aggregation across multiple AWS regions. You’d need to setup a metric math to aggregate the total
- With fewer data points, your ability to perform fine-grained aggregation is limited and inaccuragte
EBS AutoEnableIO
- When underlying hardware errors happens, aws stops the IO for that instance. Once resolved you’d need to enable the IO operation
- When Auto Enable is set up, you can expect that IO operations are re-enabled

Storage Optimised Instances
Stores data locally, optimised for instance store instances
- An instance’s EBS performance is bounded by the instance’s performance limits, or
- the aggregated performance of its attached volumes, whichever is smaller gp3: Up to 16,000 IOPS (provisioned) io1 / io2: Up to 256,000 IOPS if using Nitro-based instances st1 and sc1: Lower throughput-focused, not IOPS-optimized
- For example, to achieve
80,000IOPS forr6i.16xlarge, the instance must have at least5gp3volumes provisioned with16,000IOPS each (5volumes x16,000IOPS =80,000IOPS).
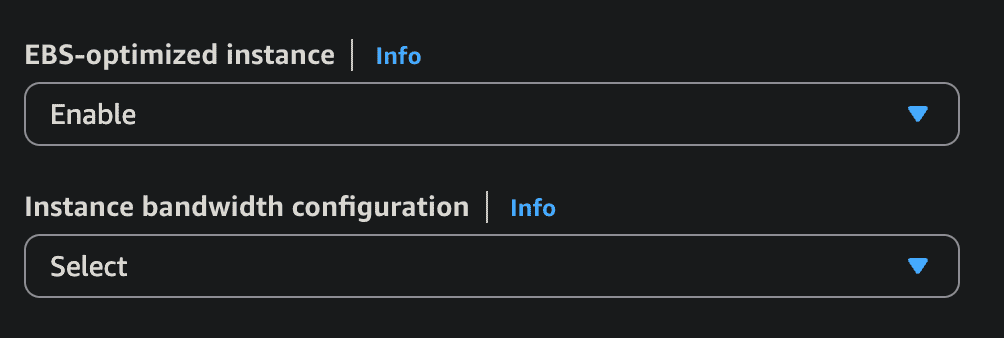
EBS Optimised instance
- The EC2 bandwidth to the EBS server will allocated more than for networking
- When you stop an instance, the data on any instance store volumes is erased. To keep data from instance store volumes, be sure to back it up to persistent storage.
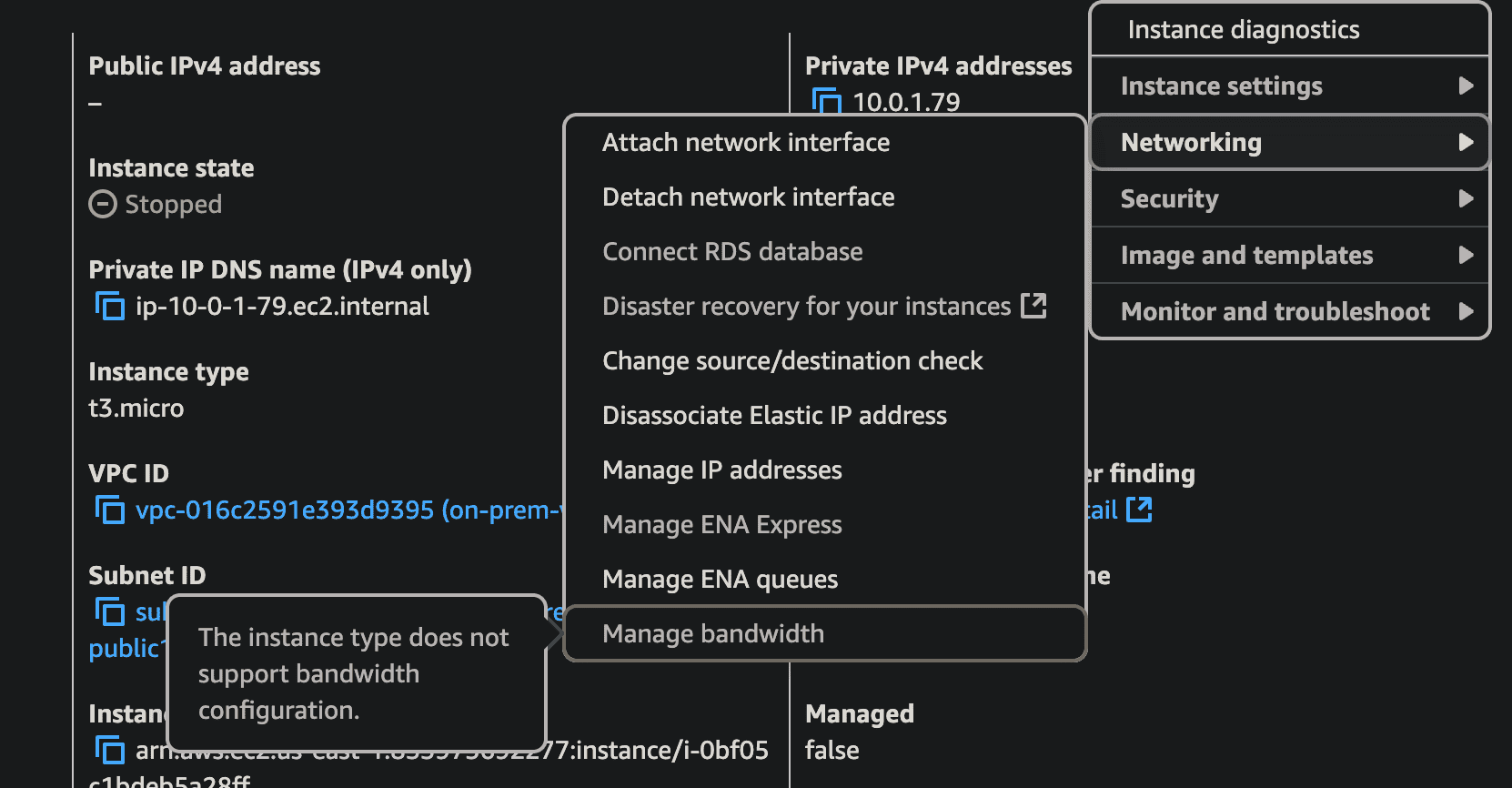
 https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ebs-optimization-performance.html
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ebs-optimization-performance.html
 Surely there’s a link
Surely there’s a link
Custom vs Default NACL
- The default NACL allows every connections,
- Upon creation of custom NACL, you’d need to add allow, and everything is denied


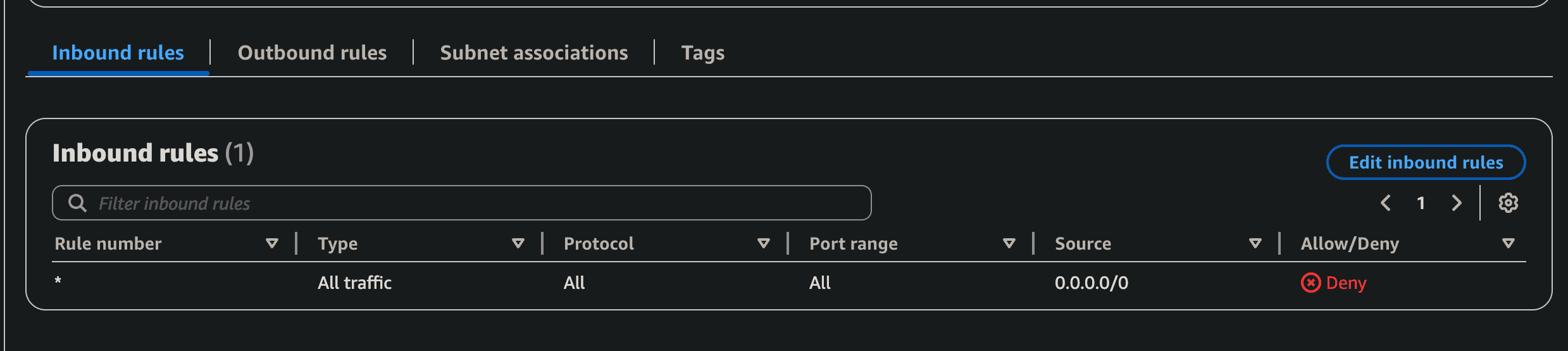
CFN Stack creation failures
create-stackapi has an optional optionon_failureDO_NOTHING,ROLLBACK(default), orDELETE
Blocking IP on NACL level vs WAF IP set
- NACLs would only make sense if:
- The IP is attacking at other network layers, or
- You want to block access to all resources (not just web apps) in the subnet.
s3 Transfer accelerator and Global Accelerator
Amazon S3 Transfer Acceleration is a bucket-level feature that enables fast, easy, and secure transfers of files over long distances between your client and an S3 bucket. Transfer Acceleration takes advantage of the globally distributed edge locations in Amazon CloudFront. As the data arrives at an edge location, the data is routed to Amazon S3 over an optimized network path.

Global Accelerator works with: Elastic IPs ALB / NLB (Application/Network Load Balancers) EC2 instances AWS services reachable via IP
Link to originalS3 is a distributed service, its not one off services like ec2 instances, that's why its physically it required AWS to create two different service
storage-gateway instance-disk-and-cache
You can create an S3 File Gateway, FSx File Gateway, Tape Gateway, or Volume Gateway on any AWS Storage Gateway Hardware Appliance in your deployment.
Adding storage
- Configure cache storage” section in the AWS Storage Gateway console will list all the disks that your instance is attached to
- For each disk you choose “Allocated to caches”
- This doesn’t requires any downtime
Resizingin
Link to original
- Removing is not possible?
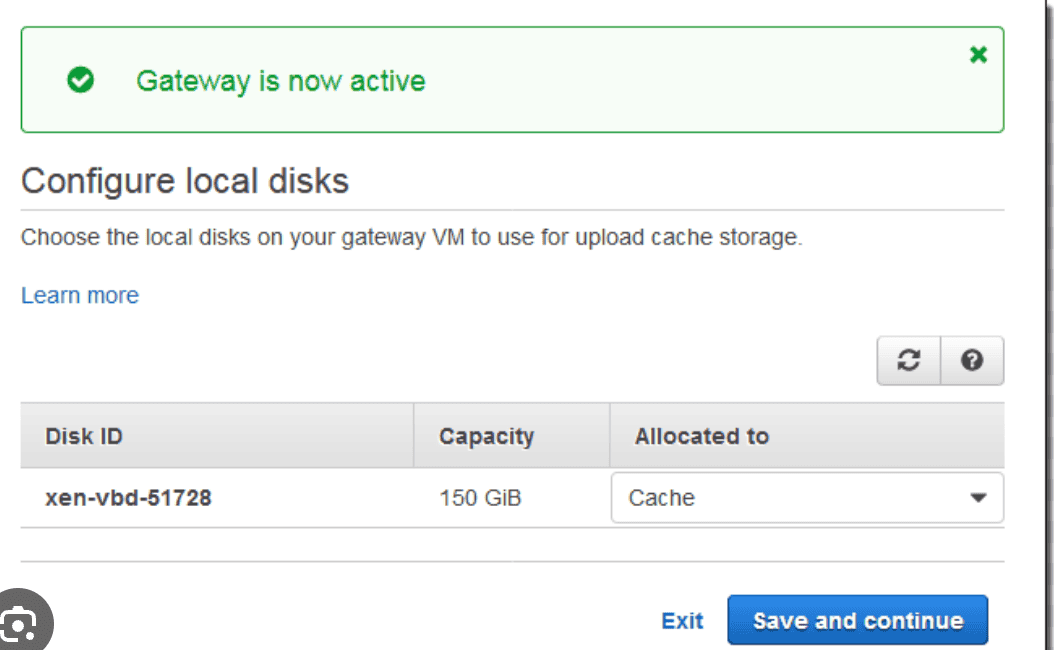
storage-gateway volume-gateway
- Deploy Storage Gateway either on-premises as a VM appliance
- Block storage using iSCSI protocol storage backed by S3
- in turn backed by EBS snapshots
Types of volume gateway
- Cached volumes
- Stored volumes
Link to originalCached Volume variant because the metrics
CacheHitPercentandCachePercentUsedare not supported in Stored Volumes
storage-gateway tape-gateway
- For backup processes based on tape storage
- uses iSCSI protocol and VTL Virtual Tape Library behind the scenes
- Works with leading backup vendors
Link to originalthe default block size for tape drives is 64 KB==, but you can increase it to improve I/O performance. The maximum block size supported is 1MB
AWS EMR - Apache Spark Health Events on your cloud resources - AWS personel health or AWS health Health Events on general - AWS Service Health
CDN vs Unlimited burst mode
Cloudfront is for improving LOAD Times Unlimited Mode in EC not improve the latency
Disk vs Volumes
Amazon EBS operates at the block level. It doesn’t know what’s going on inside the volume (like file deletions, filesystem usage, etc.). That’s the job of the operating system.
Blackhole NAT
If you delete a NAT gateway, the NAT gateway routes remain in a blackhole status until you delete or update the routes. Hence, the correct answer in this scenario is that the NAT Instance or NAT Gateway that was previously attached was deleted.
The option that says: The Internet Gateway was detached from your VPC is incorrect. Although detaching the Internet Gateway will affect the Internet connectivity of your application, this is unlikely to cause the blackhole status in your route table.
NLB - handle millions of requests per second while maintaining ultra-low latencies
AWS Trusted Advisor
High level AWS account Assessment for best practice and excellence
- Do you have public EBS, RDS snapshots? Are you using root account?
Grouped in categories
- Cost Optimsation
- Performance
- Security
- Fault Tolerance
- Service limits
- Operation excellence
There are Buisness and Enterprise plans too
Link to original
access logs
- You can enable access logs for you ALB from the
attributespanel. it is disabled by default- Logs will be sent to s3, so resource policy have to be updated
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "logdelivery.elasticloadbalancing.amazonaws.com" }, "Action": "s3:PutObject", "Resource": "arn:aws:s3:::amzn-s3-demo-bucket/prefix/AWSLogs/123456789012/*" } ] }bucket[/prefix]/AWSLogs/aws-account-id/elasticloadbalancing/region/yyyy/mm/dd/aws-account-id_elasticloadbalancing_region_app.load-balancer-id_end-time_ip-address_random-string.log.gz
- Here are the access logs entries
- It is for UNDERSTANDING but not for ALL ACCOUNTING
Here are the actions
authenticatefixed-response— Ruleforward— Ruleredirect— Rule.waf— The load balancer forwarded the request to AWS WAF to determine whether the request should be forwarded to the target. If this is the final action, AWS WAF determined that the request should be rejected. By default, requests rejected by AWS WAF will be logged as “403” in theelb_status_codefield. When AWS WAF is configured to reject requests with a Custom Response Code, theelb_status_codefield will reflect the configured response code.waf-failed— The load balancer attempted to forward the request to AWS WAF, but this process failed.Link to original
Field Description type The type of request or connection. The possible values are as follows (ignore any other values):
-http— HTTP
-https— HTTP over TLS
-h2— HTTP/2 over TLS
-grpcs— gRPC over TLS
-ws— WebSockets
-wss— WebSockets over TLStime The time when the load balancer generated a response to the client, in ISO 8601 format. For WebSockets, this is the time when the connection is closed. elb The resource ID of the load balancer. If you are parsing access log entries, note that resources IDs can contain forward slashes (/). client:port The IP address and port of the requesting client. If there is a proxy in front of the load balancer, this field contains the IP address of the proxy. target:port The IP address and port of the target that processed this request.
If the client didn’t send a full request, the load balancer can’t dispatch the request to a target, and this value is set to -.
If the target is a Lambda function, this value is set to -.
If the request is blocked by AWS WAF, this value is set to -.request_processing_time The total time elapsed (in seconds, with millisecond precision) from the time the load balancer received the request until the time it sent the request to a target.
This value is set to -1 if the load balancer can’t dispatch the request to a target. This can happen if the target closes the connection before the idle timeout or if the client sends a malformed request.
This value can also be set to -1 if a TCP connection cannot be established with the target before reaching the 10-second TCP connection timeout.
If AWS WAF is enabled for your Application Load Balancer or the target type is a Lambda function, the time it takes for the client to send the required data for POST requests is counted towardsrequest_processing_time.target_processing_time The total time elapsed (in seconds, with millisecond precision) from the time the load balancer sent the request to a target until the target started to send the response headers.
This value is set to -1 if the load balancer can’t dispatch the request to a target. This can happen if the target closes the connection before the idle timeout or if the client sends a malformed request.
This value can also be set to -1 if the registered target does not respond before the idle timeout.
If AWS WAF is not enabled for your Application Load Balancer, the time it takes for the client to send the required data for POST requests is counted towardstarget_processing_time.response_processing_time The total time elapsed (in seconds, with millisecond precision) from the time the load balancer received the response header from the target until it started to send the response to the client. This includes both the queuing time at the load balancer and the connection acquisition time from the load balancer to the client.
This value is set to -1 if the load balancer doesn’t receive a response from a target. This can happen if the target closes the connection before the idle timeout or if the client sends a malformed request.elb_status_code The status code of the response generated by the load balancer, fixed response rule, or AWS WAF custom response code for Block actions. target_status_code The status code of the response from the target. This value is recorded only if a connection was established to the target and the target sent a response. Otherwise, it is set to -. received_bytes The size of the request, in bytes, received from the client (requester). For HTTP requests, this includes the headers. For WebSockets, this is the total number of bytes received from the client on the connection. sent_bytes The size of the response, in bytes, sent to the client (requester). For HTTP requests, this includes the response headers and body. For WebSockets, this is the total number of bytes sent to the client on the connection.
The TCP headers and TLS handshake payload are not counted, and have no correlation toDataTransfer-Out-Bytesin AWS Cost Explorer.”request” The request line from the client, enclosed in double quotes and logged using the following format: HTTP method + protocol://host:port/uri + HTTP version. The load balancer preserves the URL sent by the client, as is, when recording the request URI. It does not set the content type for the access log file. When you process this field, consider how the client sent the URL. ”user_agent” A User-Agent string that identifies the client that originated the request, enclosed in double quotes. The string consists of one or more product identifiers, product[/version]. If the string is longer than 8 KB, it is truncated. ssl_cipher [HTTPS listener] The SSL cipher. This value is set to - if the listener is not an HTTPS listener. ssl_protocol [HTTPS listener] The SSL protocol. This value is set to - if the listener is not an HTTPS listener. target_group_arn The Amazon Resource Name (ARN) of the target group. ”trace_id” The contents of the X-Amzn-Trace-Id header, enclosed in double quotes. ”domain_name” [HTTPS listener] The SNI domain provided by the client during the TLS handshake, enclosed in double quotes. This value is set to - if the client doesn’t support SNI or the domain doesn’t match a certificate and the default certificate is presented to the client. ”chosen_cert_arn” [HTTPS listener] The ARN of the certificate presented to the client, enclosed in double quotes. This value is set to session-reusedif the session is reused. This value is set to - if the listener is not an HTTPS listener.matched_rule_priority The priority value of the rule that matched the request. If a rule matched, this is a value from 1 to 50,000. If no rule matched and the default action was taken, this value is set to 0. If an error occurs during rules evaluation, it is set to -1. For any other error, it is set to -. request_creation_time The time when the load balancer received the request from the client, in ISO 8601 format. ”actions_executed” The actions taken when processing the request, enclosed in double quotes. This value is a comma-separated list that can include the values described in Actions taken. If no action was taken, such as for a malformed request, this value is set to -. “redirect_url” The URL of the redirect target for the location header of the HTTP response, enclosed in double quotes. If no redirect actions were taken, this value is set to -. “error_reason” The error reason code, enclosed in double quotes. If the request failed, this is one of the error codes described in Error reason codes. If the actions taken do not include an authenticate action or the target is not a Lambda function, this value is set to -. “target:port_list” A space-delimited list of IP addresses and ports for the targets that processed this request, enclosed in double quotes. Currently, this list can contain one item and it matches the target:port field.
If the client didn’t send a full request, the load balancer can’t dispatch the request to a target, and this value is set to -.
If the target is a Lambda function, this value is set to -.
If the request is blocked by AWS WAF, this value is set to -.“target_status_code_list” A space-delimited list of status codes from the responses of the targets, enclosed in double quotes. Currently, this list can contain one item and it matches the target_status_code field.
This value is recorded only if a connection was established to the target and the target sent a response. Otherwise, it is set to -.“classification” The classification for desync mitigation, enclosed in double quotes. If the request does not comply with RFC 7230, the possible values are Acceptable, Ambiguous, and Severe.
If the request complies with RFC 7230, this value is set to -.“classification_reason” The classification reason code, enclosed in double quotes. If the request does not comply with RFC 7230, this is one of the classification codes described in Classification reasons. If the request complies with RFC 7230, this value is set to -. /conn_trace_id The connection traceability ID is a unique opaque ID used to identify each connection. After a connection is established with a client, subsequent requests from this client will contain this ID in their respective access log entries. This ID acts as a foreign key to create a link between the connection and access logs.