![]()
Encoder - Encoder understands the input text Decoder - Decodes uses the understanding of encoder and generates new piece of data from it
The decoder repeatedly feeds the sequence of input back in itself
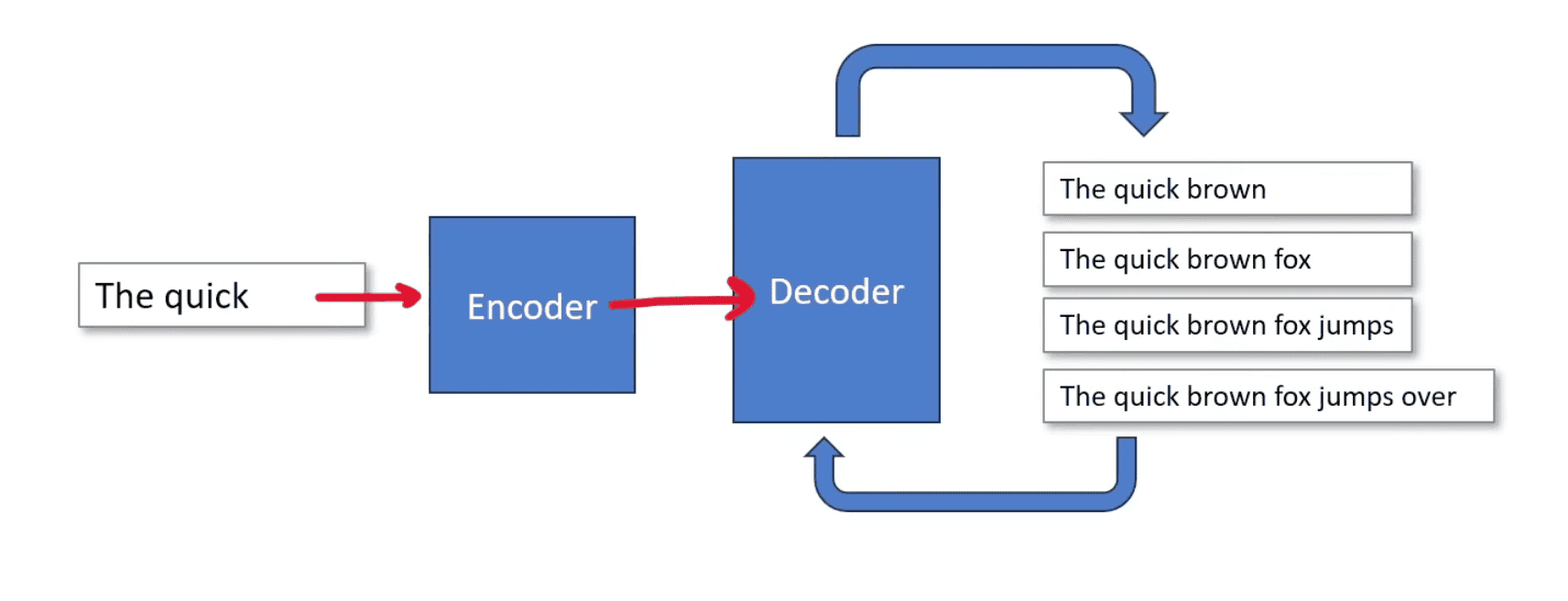
Memory - Each token holds a memory, ie as the token count increases the memory required increases, the memory usage eventually becomes exhausted
Compute - Each additional token requires more computation, the longer the sequence the more compute is required
Models as a service(s) often will have limits on combined inputs and outputs
As a consumer, its better to have conversations short and jump by summarising current into the next session, so that the token context will be reduced